|
1. 数据库表锁定原理 1.1 目前的C/S,B/S结构都是多用户访问数据库,每个时间点会有成千上万个user来访问DB,其中也会同时存取同一份数据,会造成数据的不一致性或者读脏数据.
1.2 事务的ACID原则
1.3 锁是关系数据库很重要的一部分, 数据库必须有锁的机制来确保数据的完整和一致性. 1.3.1 SQL Server中可以锁定的资源:
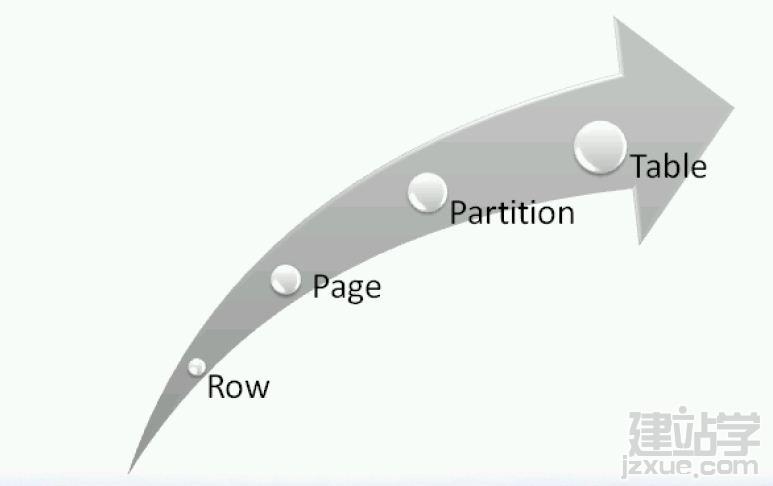
1.3.2 锁的粒度:
1.3.3 锁的升级: 锁的升级门限以及锁升级是由系统自动来确定的,不需要用户设置. 1.3.4 锁的类型: (1) 共享锁: 共享锁用于所有的只读数据操作. (2) 修改锁: 修改锁在修改操作的初始化阶段用来锁定可能要被修改的资源,这样可以避免使用共享锁造成的死锁现象 (3) 独占锁: 独占锁是为修改数据而保留的。它所锁定的资源,其他事务不能读取也不能修改。独占锁不能和其他锁兼容。 (4) 架构锁 结构锁分为结构修改锁(Sch-M)和结构稳定锁(Sch-S)。执行表定义语言操作时,SQL Server采用Sch-M锁,编译查询时,SQL Server采用Sch-S锁。 (5) 意向锁 意向锁说明SQL Server有在资源的低层获得共享锁或独占锁的意向。 (6) 批量修改锁 批量复制数据时使用批量修改锁 1.3.4 SQL Server锁类型 (1) HOLDLOCK: 在该表上保持共享锁,直到整个事务结束,而不是在语句执行完立即释放所添加的锁。 (2) NOLOCK:不添加共享锁和排它锁,当这个选项生效后,可能读到未提交读的数据或“脏数据”,这个选项仅仅应用于SELECT语句。 (3) PAGLOCK:指定添加页锁(否则通常可能添加表锁)。 (4) READCOMMITTED用与运行在提交读隔离级别的事务相同的锁语义执行扫描。默认情况下,SQL Server 2000 在此隔离级别上操作。 (5) READPAST: 跳过已经加锁的数据行,这个选项将使事务读取数据时跳过那些已经被其他事务锁定的数据行,而不是阻塞直到其他事务释放锁, READPAST仅仅应用于READ COMMITTED隔离性级别下事务操作中的SELECT语句操作。 (6) READUNCOMMITTED:等同于NOLOCK。 (7) REPEATABLEREAD:设置事务为可重复读隔离性级别。 (8) ROWLOCK:使用行级锁,而不使用粒度更粗的页级锁和表级锁。 (9) SERIALIZABLE:用与运行在可串行读隔离级别的事务相同的锁语义执行扫描。等同于 HOLDLOCK。 (10) TABLOCK:指定使用表级锁,而不是使用行级或页面级的锁,SQL Server在该语句执行完后释放这个锁,而如果同时指定了HOLDLOCK,该锁一直保持到这个事务结束。 (11) TABLOCKX:指定在表上使用排它锁,这个锁可以阻止其他事务读或更新这个表的数据,直到这个语句或整个事务结束。 (12) UPDLOCK :指定在读表中数据时设置更新 锁(update lock)而不是设置共享锁,该锁一直保持到这个语句或整个事务结束,使用UPDLOCK的作用是允许用户先读取数据(而且不阻塞其他用户读数据),并且保证在后来再更新数据时,这一段时间内这些数据没有被其他用户修改。 (本段摘自CSDN博客: http://blog.csdn.net/zp752963831/archive/2009/02/18/3906477.aspx) (责任编辑:admin) |