Liwu_Items表,CreateTime列建立聚集索引
第一种,sqlserver2005特有的分页语法
declare @page int
declare @pagesize int
set @page = 2
set @pagesize = 12
SET STATISTICS IO on
SELECT a.* FROM (
SELECT ROW_NUMBER() OVER (ORDER BY b.CreateTime DESC) AS [ROW_NUMBER], b.*
FROM [dbo].[Liwu_Items] AS b ) AS a
WHERE a.[ROW_NUMBER] BETWEEN @pagesize + 1 AND (@page*@pagesize)
ORDER BY a.[ROW_NUMBER]
结果:
(12 行受影响)
表 'Liwu_Items'。扫描计数 1,逻辑读取 7 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
逻辑读是7次
执行计划:

主要开销都在聚集索引扫描了。
第二种,用两个top分别正序和倒序排列,共另个子查询来实现分页,
declare @page int
declare @pagesize int
set @page = 2
set @pagesize = 12
SET STATISTICS IO on
select * from (
select top (@pagesize) * from
(select top (@page*@pagesize) * from Liwu_Items order by CreateTime desc) a
order by CreateTime asc) b
order by CreateTime desc
结果
(12 行受影响)
表 'Liwu_Items'。扫描计数 1,逻辑读取 7 次,物理读取 0 次,预读 317 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
执行计划

执行计划和第一种差不多,但两个排序占的资源挺多的。
第三种,最垃圾的一种,用not in字句实现的,如下
declare @page int
declare @pagesize int
set @page = 2
set @pagesize = 12
SET STATISTICS IO on
select top(@pagesize) * from Liwu_Items
where ItemId not in(
select top((@page-1)*@pagesize) ItemId from Liwu_Items order by CreateTime desc)
order by CreateTime Desc
结果
(12 行受影响)
表 'Worktable'。扫描计数 1,逻辑读取 70 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'Liwu_Items'。扫描计数 2,逻辑读取 18 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
性能最差,对两个表进行处理,逻辑读都很高,汗。
执行计划
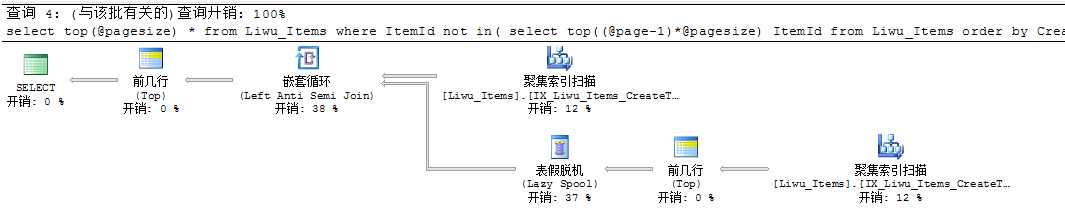
这执行计划都看不懂,嵌套循环和表假脱机占了很大的资源。
总结:第二种分页方法和第一种分页方法效率差不多,但第二种可用于老版本的sqlserver甚至access,最后一种别用。
(责任编辑:admin)