|
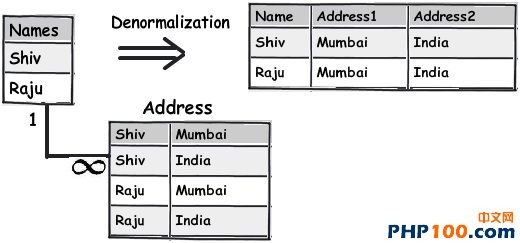
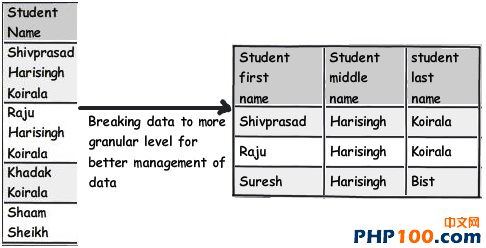
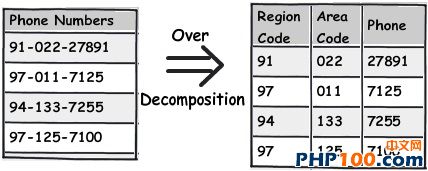
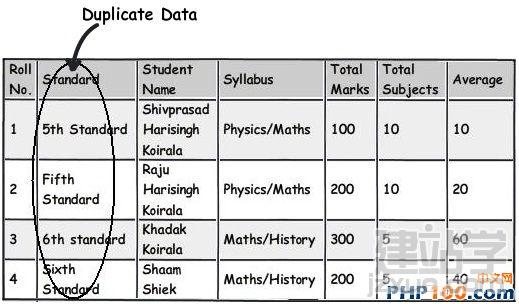
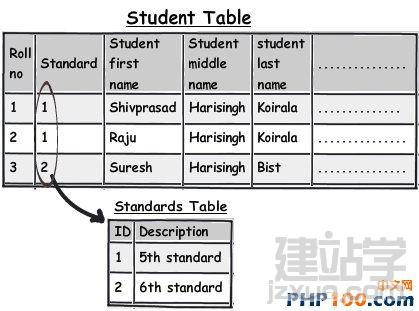
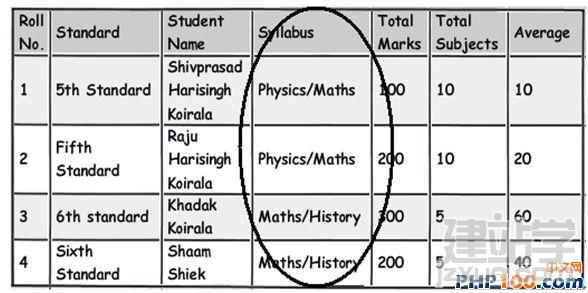
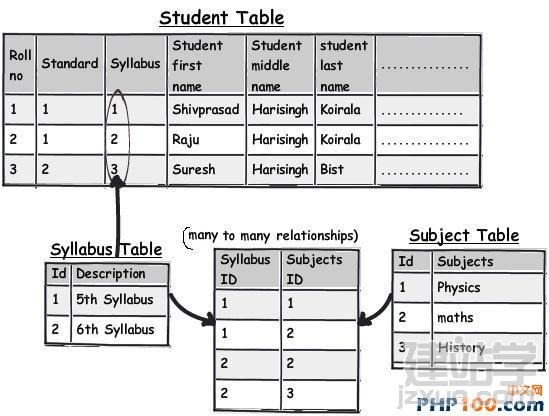
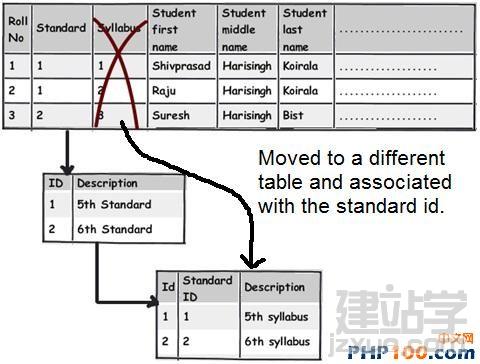
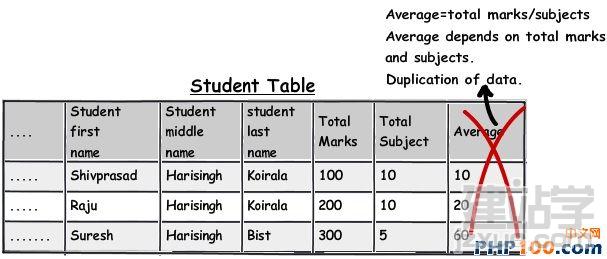
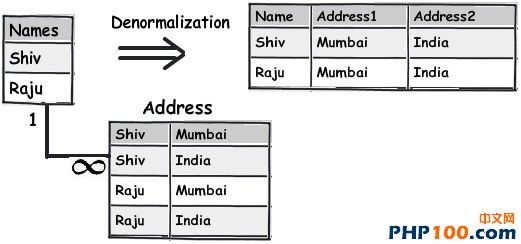
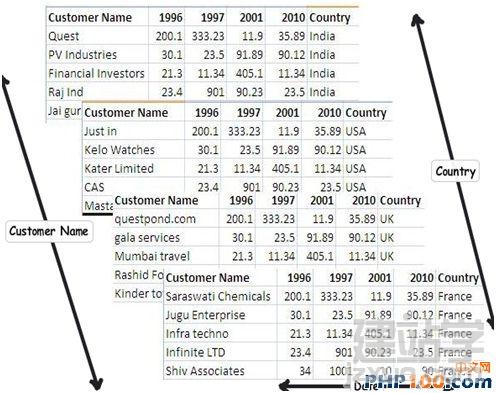
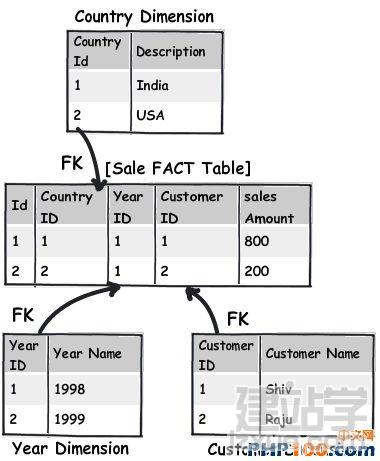
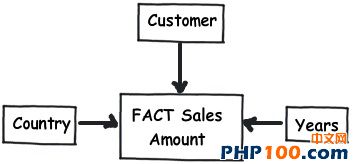
在日常工作中,当我们遇到海量数据时,如何从中挑选出自己想要的数据呢?是盲目的查找,还是寻求新的解决方案亦或是通过技巧来获取?开发者在设计一个 数据表单时,往往会遵循三条常用形式,他们认为常规模式是设计的唯一途径。然而由于开发者一开始就抱有这种心态,使数据表单设计变得墨守成规,阻碍了它的 创新。 作者Shivprasad 从平时的工作项目中积累了一些经验,向我们介绍了11款制作数据表单技巧,当设计到数据表单制作时,不妨以此来参考,以丰富我们的应用经验。 Rule 1:弄清(OLTP或OLAP)应用的本质是什么? 当开始制作数据表单设计时,首先,要分析你设计的这个程序的本质是什么?是事务性还是分析性的?你会发现许多开发者会默认应用常规化规则,随后才考虑性能问题而不考虑应用的本质。 关于事务性和分析性,一起来看下两者区别。 Transactional:这种应用,用户对CRUD较为感兴趣,即创建、读取、更新和删除记录。这种数据,官方名称之位OLTP。 Analytical:用户对分析、报告、预测等方面感兴趣。这类数据库很少有嵌入和更新。主要目的是为了尽快获取和分析数据。官方名称之为OLAP。 换句话说,如果你想以嵌入、更新、删除为重点,可选择常规化的表单设计或者创建一个简单的非常规化的数据架构。 下面是一个简单的图表,左侧显示名称和地址,采用非规范化结构设计出的一款简单的常规表单。 Rule 2:将数据按照逻辑思维分成不同的块,让生活更简单 这个规则其实就是 “三范式” 中的第一范式。这样设计的目标,是为了当你需要查询套多的字符串解析功能时,如子串,charindexetc,它能为你提供这项功能。 例如,注意观看下面的图表,如果你想查询某个学生的姓名,通过“Koirala”和“Harisingh”来进行区分。 因此,更好的方法就是打破数据逻辑思维,以便我们编写更加简洁、容易查询的表单。 Rule 3:当数据太多时,rule 2不可用 开发者们的思维有时很单一,如果你告诉他们某种方式,他们会一直这么做下去,要知道过度的使用会造成不必要的麻烦。正如我们之前谈到的rule 2,首先要进行分解,明确自己的需求。例如,当你看到电话号码字段时,你可以在ISD代码上进行操作区分这些电话号码(直到满足你的需求)。尽管这是不错 的方法,但会给你带来更多的并发症。 Rule 4:将重复、不统一的数据视作你最大的敌人 聚焦和重构复制数据。我比较担心的不是复制数据所需要的磁盘空间而是它因此而造成的混乱。 从下面的图表中,“5th Standard”和“Fifth standard”意思是相同的,你可以说是因为数据或者验证数据录入到你的系统原因,如果你想通过报表来显示他们的不同之处,从用户的角度开看,这是非常困难的。 其中一个解决方法就是将不同的任务栏把相同的数据通过新建一个键入值联接在一起。如图。我们通过创建一个新的条目“Standards”即可将数据重新排,显示相同的部分。 Rule 5:注意被分隔符分割的数据 前面的规则2即“第一范式”提到避免数组重复,如图所示。如果你看到教学大纲紧密排列在一起,这个领域中需要很多数据来填充,这种我们称之为“重复数组”。如果我们必须操纵这些数据,单凭查询是很困难的,我甚至还怀疑是否具备这个查询功能。 这些带分隔符的数据需要特别注意,如何利用更好的方法将这些数据移动到一个不同的任务栏中,以便更好的分类呢?如图: 如图所示,可以看到我创建了一个独立的教学科目条目,然后列出了与之有相关联的科目。这种方法主要适用于在教学大纲领域,避免过多的重复和数据分隔符中。 Rule 6:当心数据依赖 观察该领域中的部分列表。如图,我们创建了roll number和standard,可以看到教学科目紧密联系在一起,但与学生学习的科目没有直接关联。如果我们想给每位学生更新教学科目,这似乎看起来是 不符合逻辑的,但是通过键入standard条目转换这些数据就可达到目的。 这个规则告诉我们“所有的键入都应该依赖主键”。All keys should depend on the full primary key and not partially。 Rule 7:选择派生列 如果你想进行OLTP应用首先得筛选出派生列,在OLAP中我们需要做一些求和,方可获得uixie很好的性能。如图,求的平均数需要利用marks和subject两列。 这个规则被称为第三范式,“不应该有依赖于非主键的列”(No columns should depend on other non-primary key columns)我个人认为是不能盲目使用此规则。如果该数据是计算过的数据,看清状况然后在决定实施第三范式。 Rule 8:如果性能很关键,不要避开冗余数据 如果你迫切的考虑到性能规范化问题,通常情况下需要连接许多列表以及减少增加非规范化的列表以便来提高数据图表性能。 Rule 9:数据多、繁杂 OLAP项目主要是为了处理数据繁多,例如,如图所示,假如你想获得每个国家、每个用户、每年的销售额度。对于这种情况,你可以创建一个实际销售列表条目(sales fact table)。
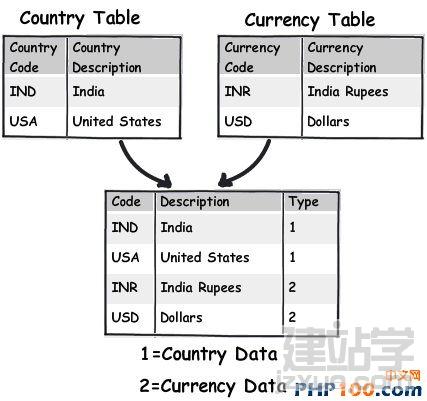
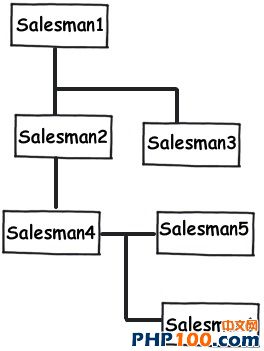
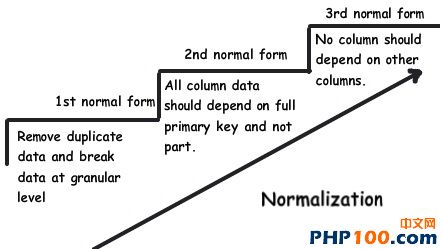
Rule 10:设计name value table列表 明值表意味着它有一些键,这些键被其他数据关联着。如图所示,我们需要弄清楚currency table (货币列)和country table(国家列),图中键入值(数字部分)显示的就是我们所需要的数据。 通过创建键入值(Type)来显示出不同区域的数据。 Rule 11:无限制结构数据,自定义PK和FK 我们会经常碰到一些无限父子分级结构的数据。例如:考虑到一个多层次的营销方案,其中一个销售人员可以领导多个销售人员。在这种情况下,你可以使用自定义的主键和设置外键来帮助你实现统一。 您可以根据自身的项目需求选择不同的数据处理方法。如下所示:三种常规范式。 |